Leia esta página em Português
Technology
Querido Diário is an ambitious free software project and is receiving contributions from technology community in order to evolve. Find out more about the technological side of the initiative.
Understanding Querido Diário
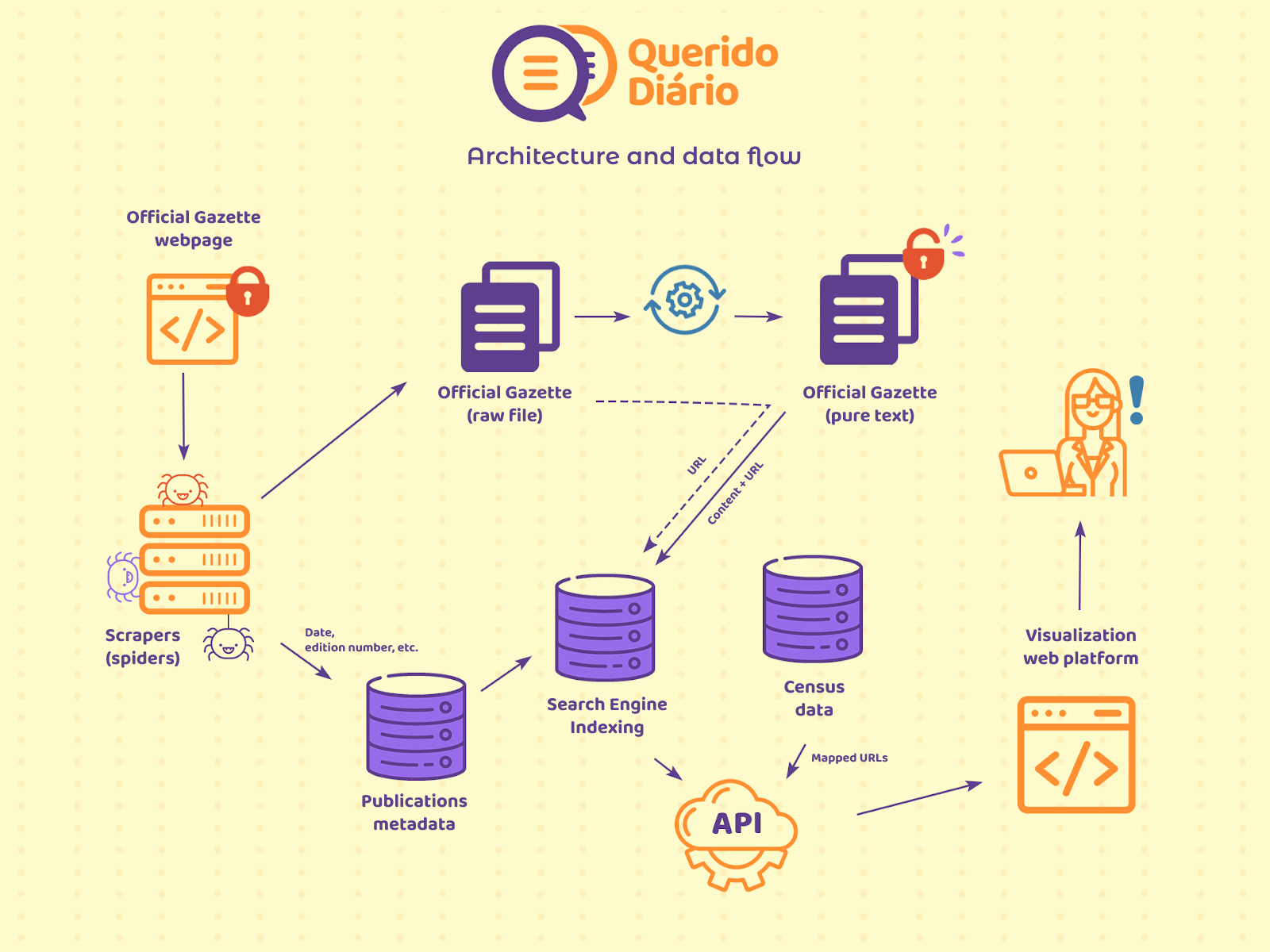
For the official gazette file to travel from the municipality's website to be accessible to you through Querido Diário, it goes through a few stages:
The data collection where we put scraping robots to work on our behalf by visiting the publishing websites of the integrated municipalities every day to obtain the original official gazette files. Here, we use Python and Scrapy for scraping and the PostgreSQL database for storage.
In data processing we process the collected file, mainly by extracting the textual content of closed files (usually PDFs) into an open and searchable format. And it's the use of Python, Apache Tika (extraction) and OpenSearch (textual search engine) that make this possible.
In data sharing, we have created means of accessing our data. Anyone can search in a user-friendly way with the search engine on the home page of this site, developed in TypeScript and Angular. And any computer can search programmatically via the Public API, developed in Python with FastAPI.
The following image summarizes how the pieces interact in order to have this complete data flow.
Documentation
This was just a “Hello, World!” to Querido Diário. To get to know it more, there are more detailed sections in the technical documentation.
Contribute
You can contribute in different ways, from creating knowledge through research in the official gazettes to improving the project's code.
Using data to create relevant knowledge
We are committed to facilitating access to official gazettes because we believe they are valuable information for society. Therefore, using them to create knowledge about the country from within the municipalities is a very meaningful way of contributing and it helps us to concretize the importance of Querido Diário. In particular, people with a background in journalism, public administration, law, sociology, history, etc., can benefit from our data in their investigations or research.
If you produce content from consultation with Querido Diário, or are interested in doing so, please contact us by e-mail(queridodiario AT ok.org.br). That way, we have a better understanding of the uses that are being made and we can also report your findings here on the site.
Improving and extending code
Querido Diário is a combination of free softwares. Since its conception, most of the technical progress has been made by an incredible developer community, which has enabled us to achieve the current structure of the project, as well as continuing to strengthen us on a daily basis.
All the code is hosted in repositories on GitHub and you can contribute where it is most interesting and compatible. The main repositories and their challenges are:
Scrapers: develop or give maintenance to scraper robots for the official gazette websites of all Brazilian municipalities. Access github.com/okfn-brasil/querido-diario
Data Processing: use Data Science to process the raw text of different types of official gazettes. Access github.com/okfn-brasil/querido-diario-data-processing
Frontend: improving and expanding the site's resources and tools. Access github.com/okfn-brasil/querido-diario-frontend
Joining the community
Whether you're interested in data, code or pure curiosity, join our community. We have several thematic chats on OKBR's Discord server, where we talk about Querido Diário, organize its technical development, provide support by answering questions and organize events. Recurring meetings also take place in this server, precisely because they are open for anyone to participate.
Access go.ok.org.br/discord
To make it easier to keep track of the various activities, we always keep an updated calendar for the community. You can sign up to receive notifications about events at a frequency of your choice.
Todo o conteúdo do Querido Diário está disponível sob a licença Creative Commons Atribuição 4.0 Internacional, o que significa que pode ser compartilhado e reutilizado para trabalhos derivados, desde que citada a fonte.
Pessoas desenvolvedoras: temos dados abertos e API ♥ Conheça e contribua com o desenvolvimento